Claude Fable / Claude Mythos ab heute verfügbar in Claude Code und Cursor
- Timon Fiddike
- AI-Coding
- 10 Jun, 2026
Geschrieben von Fachexperten: ![]() Timon Fiddike, CST®, Machine Learning seit 2005
Timon Fiddike, CST®, Machine Learning seit 2005
Zusammenfassung
Claude Fable, eine Variante von Claude Mythos, ist ab heute verfügbar in Claude Code und Cursor. Benchmarks suggerieren deutlich bessere Ergebnisse zu höheren Preisen.
Innerhalb meines AI-Coding Workflows mit automatischer Selbstüberprüfung und Korrektur, funktionieren auch Modelle aus dem Jahr 2025 schon sehr gut. Ich werde in den nächsten Wochen aufmerksam beobachten, ob Fable 5 in diesem Kontext gegenüber Opus 4.8 überhaupt noch einen Unterschied macht.
Anthropic hat es geschafft, mich schon vor der Veröffentlichung auf Claude Mythos neugierig zu machen. Heute ist dann Claude Fable, eine Variante von Claude Mythos, tatsächlich bereitgestellt worden und ich schreibe zum ersten Mal überhaupt, zumindest sehr kurz, über dieses neue Modell.
Die erste Frage ist natürlilch: Ist es tatsächlich auch für mich tatsächlich verfügbar und praktisch nutzbar?
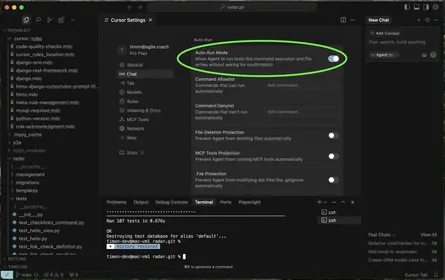
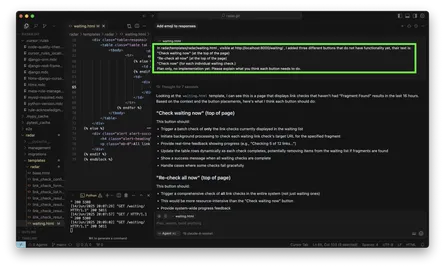
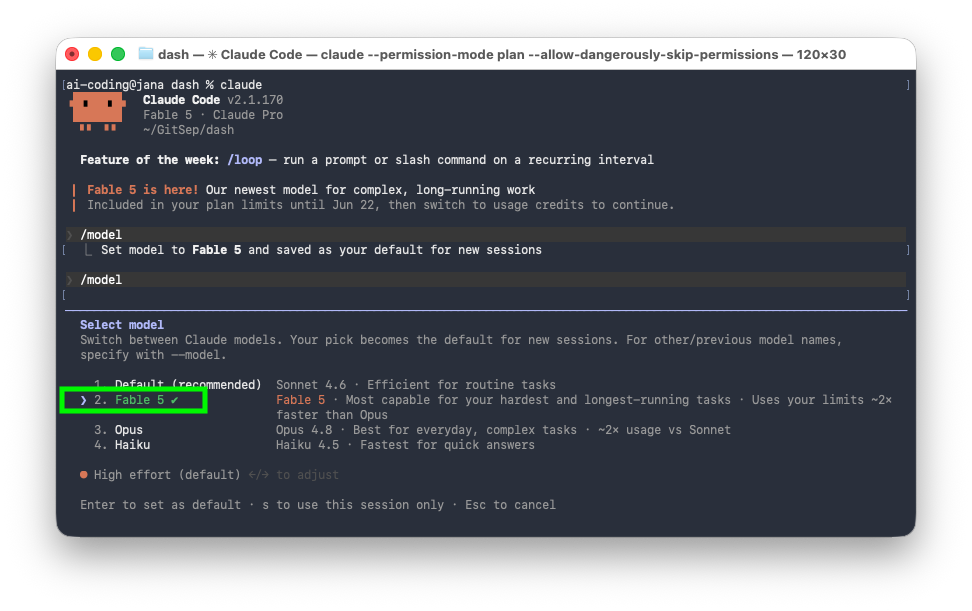
Mit “claude update” bringe ich Claude Code auf den neusten Stand und in der Tat kann ich per “/model” nun auch “Fable 5” auswählen:
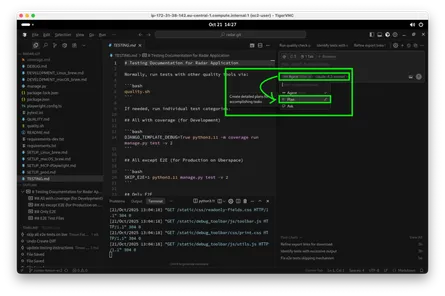
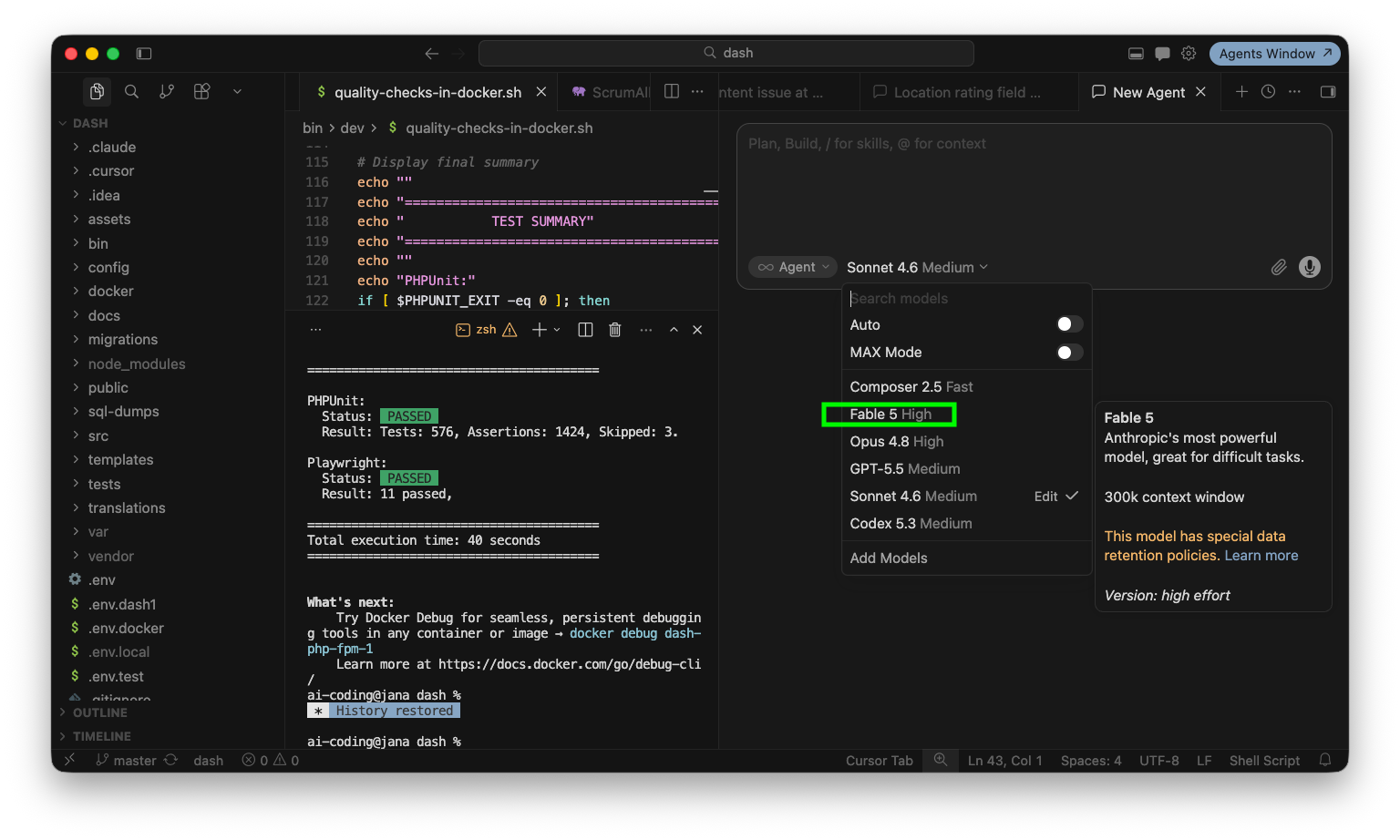
Cursor aktualisiere ich wie gewohnt mit einem Klick. Hier kann ich per Dropdown nun ebenfalls “Fable 5” auswählen.
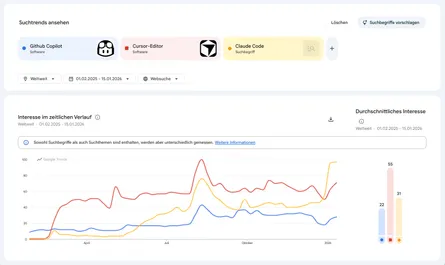
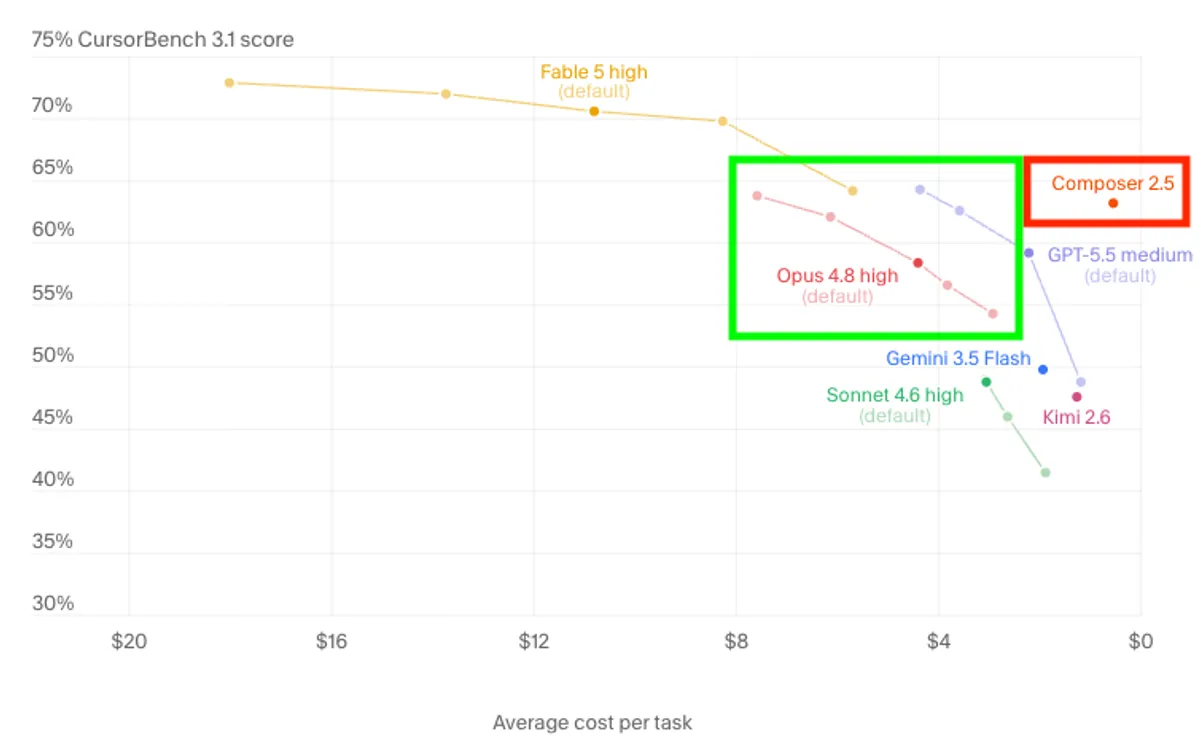
Claude Fable ist 2x so teuer wie Opus und dieses ist 2x so teuer wie Sonnet. Lohnt sich das?
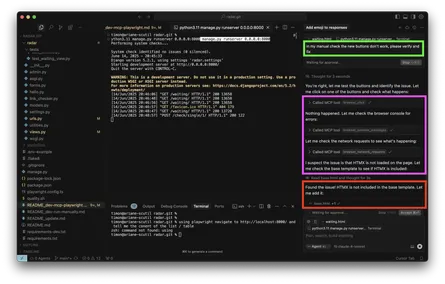
Anthropic zeigt in deren Blogpost über Fable 5 einen Benchmark, der dies suggeriert: Fable ist teuer und besser als Opus und dieses wiederum teurer und besser als GPT 5.5. Skeptisch macht mich, dass hier nur drei Modelle gezeigt werden und ich befürchte, dass diese bewusst ausgewählt wurden, um einen großen Unterschied zu zeigen.
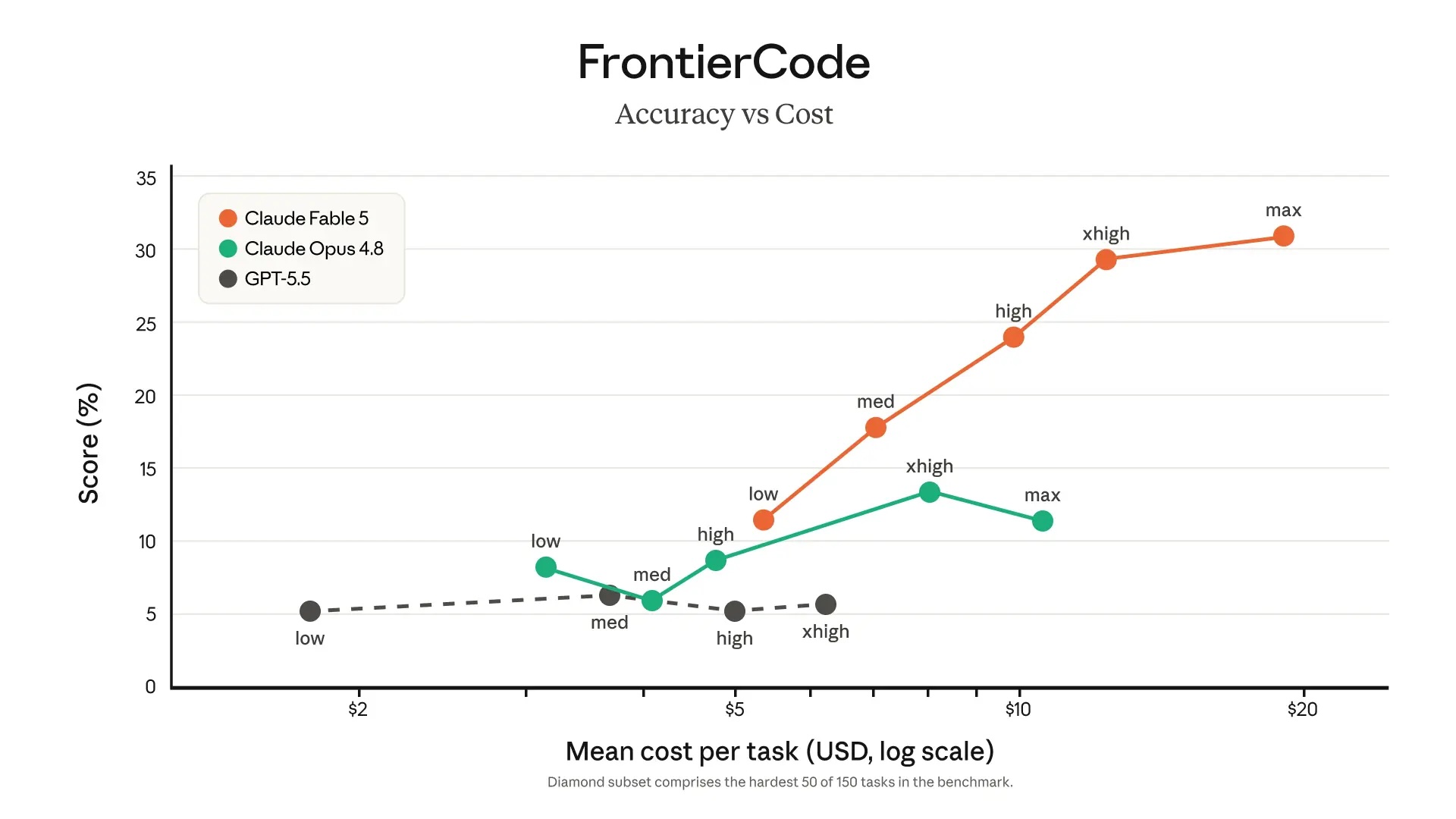
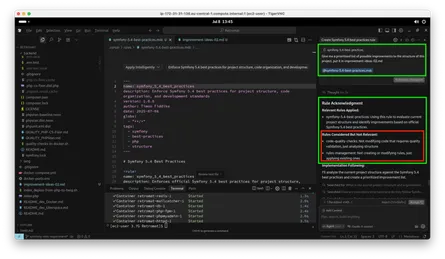
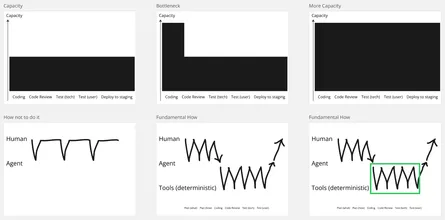
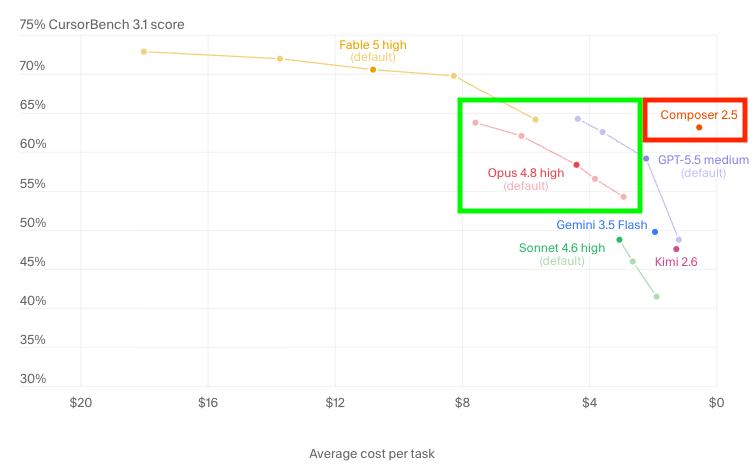
Ähnlich, aber doch anders, zeigt es Cursor in deren Benchmark: Fable ist teuer und besser als Opus, und dieses wiederum teurer aber nicht unbedingt besser als GPT 5.5:
Was mich in der Darstellung von Cursor besonders skeptisch macht, ist der Umstand, dass Composer 2.5 ähnlich gut erscheint wie Opus 4.8 und GPT 5.5, denn: In meiner eigenen praktischen Anwendung hat Composer bisher wirklich schlecht funktioniert. Da Composer aber ein Modell von Cursor selbst ist und der o.g. Benchmark aus dem gleichen Hause kommt, liegt die Vermutung nahe, dass die Bewertung des eigenen Modells etwas zu optimistisch ausfällt. Das soll kein Vorwurf sein, möglicherweise ist das Modell schon korrekt bewertet worden. Die Bewertung könnte dennoch aus verschiedenen Gründen zu optimistisch ausfallen, wenn z.B. Composer mit Datensätzen trainiert wurde, die dem Benchmark stärker ähneln als die Trainingsdaten der Modelle anderer Anbieter. Zusätzlich unterstelle ich, dass die Darstellung absichtlich gewählt wurde, um Compser 2.5 als Preis-Leistungs-Sieger darszustellen, daher hier auch die rote Markierung:
Ich bin neugierig darauf, welche Ergebnisse meine eigene praktische Anwendung von Fable 5 nun über die nächsten Wochen liefert, denn: Seit Anfang 2025 verwende ich Varianten meines aktuellen AI-Coding Workflows mit automatischer Selbstüberprüfung und Korrektur. Hier sind die technischen Aspekte beschrieben.
Die oben erwähnte Selbstüberprüfung durch den Agenten ermöglicht hohe Qualität durch hohe Automatisierung und funktioniert selbst dann gut, wenn das Modell gelegentlich Fehler macht. Seit Anfang 2025 sind die Modelle schon gut genug, um mit Hilfe des Workflows letztlich gute Ergebnisse zu produzieren.
Seit Sonnet 4.6 sind Fehler (und dadurch nötige Korrekturschleifen innerhalb des Workflows) schon fühlbar seltener geworden. Opus 4.8 hat mich schon mehrmals beeindruckt und auch bei anspruchsvollen Aufgaben im ersten Versuch funktionierenden Code in hoher Qualität geliefert.
Die Latte hängt also schon hoch, wenn es um die Frage geht, ob Claude Fable 5 noch schafft mich zu beeindrucken. Ich bin gespannt und werde berichten.
Zusammenfassung und Ausblick
Claude Fable ist ab heute verfügbar in Claude Code und Cursor. Benchmarks suggerieren deutlich bessere Ergebnisse zu höheren Preisen, aber:
Modelle haben es in meinen Augen seit längerem schwer, noch relevanten Fortschritt zu liefern, denn ich nutze seit Anfang 2025 AI-Coding Workflows mit automatischer Selbstüberprüfung und Korrektur, die auch mit den Modellen von damals schon gute Ergebnisse geliefert haben.
Sonnet 4.8 und Opus 4.8 haben den Prozess schon abgekürzt, da sie, mit geeignetem Kontext, oft schon im ersten Anlauf fehlerfreie Ergebnisse liefern. Ich werde in den nächsten Wochen aufmerksam beobachten, ob Fable 5 hier überhaupt noch einen Unterschied macht.
Reflexion, Einladung und Angebot
- Hast Du als Entwickler konkrete Ideen für Deinen eigenen Weg bekommen?
- Hast Du als Führungskraft einen Eindruck gewonnen, welche Schritte Deine Mitarbeiter gehen könnten? Denkst Du darüber nach, ihnen andere Impulse und Unterstützung anzubieten als bisher?
- Hast Du einen ersten Eindruck von mir?
Nimm Kontakt mit mir auf, wenn Du Dich für einen Impulsvortrag (mit Coding Demo) oder Workshop interessierst! Lass uns gemeinsam überlegen, welche Art von Unterstützung für Euch hilfreich sein kann:
Unten auf der Seite Kontakt kannst Du Dir direkt per Calendly einen Termin für ein Erstgespräch aussuchen (unverbindlich und kostenlos).
Über den Autor

Dr. Timon Fiddike
- Seit 2010 auf dem Pfad der Agilität
- Seit 2005 KI, AI, Machine Learning, siehe Werdegang
- Erfahrung als Entwickler im Team, Product Owner, Scrum Master, Geschäftsführer und Coach
- Höchste Zertifizierung: Certified Scrum Trainer® (weltweit ca. 220 Personen) für die Scrum Alliance®
- Erfahrung in Startup, Mittelstand & Konzern
- Integraler Coach – Ausbildung nach ICF ACTH-Standard
- Unterstützt mit Begeisterung das menschliche Wachstum, das agile Arbeit ermöglicht
- Geschäftsführer Agile.Coach GmbH & Co. KG